Subtotal $0.00






Email : 74
Anthropic’s Claude AI has just received a major update with the release of Claude Opus 4.7 (April 2026). This update brings significant advances in coding and agentic tasks, better vision understanding, and robust performance across benchmarks. The latest Claude models (Opus and Sonnet series) remain competitively priced (roughly $5/$25 for Opus and $3/$15 per million tokens). Developers gain powerful new controls (adaptive thinking, effort tuning) and higher token limits (up to 1M context, 128K outputs) for long-form tasks. In side-by-side tests, Claude Opus 4.7 outperforms its predecessor and even matches or exceeds other leading models in complex reasoning and coding benchmarks. This article explains what’s new, how it compares to GPT-4/GPT-4o and Gemini, and what it means for real-world AI projects.
Claude’s Evolution and Opus 4.7 Release
Claude is Anthropic’s family of large language models (LLMs), with Sonnet and Opus tiers for different use cases. Sonnet models (e.g. 4.6) target general usage and are available on free and paid plans, while Opus models (e.g. 4.7) are Anthropic’s flagship models for advanced reasoning and coding. In April 2026, Anthropic announced Claude Opus 4.7 as its “most capable generally available model to date”. Opus 4.7 builds on the strengths of Opus 4.6 (released Feb 2026) and Sonnet 4.6 (Feb 2026). It is available across Claude’s API, apps, and all major cloud platforms (AWS Bedrock, Google Vertex, Microsoft Foundry).
Opus 4.7 introduces key improvements for agentic and coding tasks: it handles complex, multi-step workflows with greater autonomy and accuracy. It outperforms Opus 4.6 by large margins on difficult coding benchmarks (e.g. raising success from ~53% to 64% on a standard agentic coding test). It also features substantially better vision and multimodal understanding: it can process higher-resolution images and generate more polished visual outputs (documents, slides, GUIs). Anthropic notes that while Opus 4.7 is not as broadly capable as its unreleased research model “Claude Mythos Preview” (used for advanced security tasks), it still beats Opus 4.6 across a wide range of evaluations. Early feedback from partners confirms 4.7’s strengths in planning and long-horizon reasoning: testers report it self-plans multi-agent workflows and executes long coding tasks with fewer dead-ends.
Key Features and Improvements
Claude Opus 4.7 and Sonnet 4.6 bring a host of new capabilities to developers and end-users. Key enhancements include:
- Advanced Coding & Agents: Opus 4.7 is now Anthropic’s state-of-the-art coding assistant. It “takes complicated requests and actually follows through, breaking them into concrete steps, executing, and producing polished work”. Its code generation, review, and debugging are stronger than ever. It sustains autonomous agentic tasks for longer and plans complex multi-system workflows with minimal supervision.
- Extended Context & Memory: Claude now supports context windows up to 1 million tokens (released in beta on 4.6, now generally available on 4.7) at standard pricing. This means entire codebases, contracts or research libraries can be given in one prompt. 4.7 also introduced a new tokenizer and longer output budgets (up to 128K tokens), so developers can pull long-form reasoning and multi-step results without hitting limits. Anthropic also added “thinking” controls (adaptive planning) and a task-level
effortsetting to fine-tune how deeply the model reasons. - Multimodal Vision: The model now interprets images with higher resolution. For example, it can accurately read and reason about detailed diagrams or GUI screenshots, and generate more visually polished outputs (slides, wireframes). This makes Claude Opus 4.7 better at creative design tasks and interpreting visual data.
- Tool Use & Integration: Claude continues to excel at “computer use” tasks (simulating mouse/keyboard actions). Each new release brings stronger performance on OSWorld-style benchmarks. Opus 4.7 includes all the latest tools: web search, code execution, text editing, spreadsheet tools, and the new Claude Managed Agents (build autonomous chains of tools) are in public beta. Developers can now incorporate file attachments (PDF, images), use a built-in Files API, and leverage a command-line interface (ANT) for automation. In Claude Code, features like persistent Memory (notes stored in files), Prompt Caching, and Adaptive Thinking give you finer control. For example, the CLI
/claude-api migratecommand can automatically update your codebase to use new model names and parameters when migrating to 4.7.
Before these updates, Sonnet 4.5 (Sep 2025) and Sonnet 4.6 (Feb 2026) delivered a major step-up in similar ways (better long-context reasoning, coding, and computer use). Notably, Sonnet 4.6 closed much of the gap with Opus models on many tasks, often preferred by users for being less “overengineered”. In fact, in early tests most developers chose Sonnet 4.6 over Sonnet 4.5 about 70% of the time, even preferring it to the frontier Opus 4.5 nearly 60% of the time.
Performance and Benchmarks
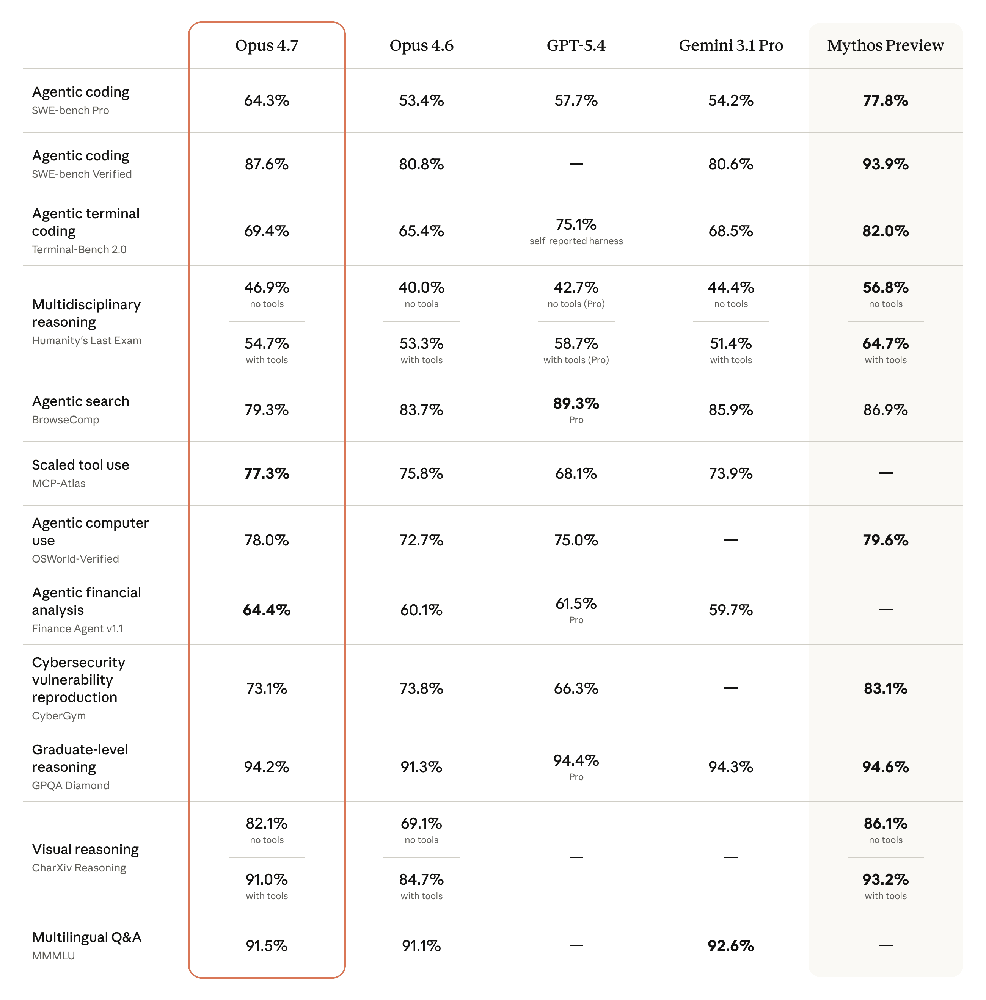
Figure: Claude Opus 4.7 performance on challenging tasks, compared to its predecessor and other advanced models (data from Anthropic). Claude 4.7 (Opus 4.7) achieves higher scores on coding and multi-step reasoning benchmarks than Opus 4.6, and is competitive with the best-in-class models.
Anthropic reports that Claude Opus 4.7 sets new performance records in many evaluations. Internal tests show it outperforms Opus 4.6 on virtually every measure, especially for agentic coding and complex reasoning. For instance, on a state-of-the-art agentic coding benchmark, Opus 4.7 solved ~64% of problems correctly versus ~53% for 4.6. On graduate-level reasoning tests, it scored ~94.2% (vs 91.3%), and it excelled in multilingual Q&A (MMMLU ~91.5% vs 91.1%).
When compared to other industry models, Claude 4.7 holds its own. Anthropic cites that Opus 4.6 (the predecessor) had already beaten OpenAI’s then-top model (GPT-5.2) on real-world work tasks by a large margin. In practice, GPT’s current counterparts are the new GPT-5.4 (also known as GPT-4o, a cheaper variant) and Google’s Gemini 3.1 Pro. GPT-5.4 is priced roughly $2.50/$15 per million tokens, and Gemini 3.1 Pro about $2.00/$12. Claude Opus 4.7’s pricing ($5/$25) is higher, but it offers much larger context (1M tokens) at a single flat rate. In head-to-head tasks, Claude often leads: for example, on a new browsing and search benchmark (DeepSearchQA), Opus 4.6 scored higher than GPT models, and Sonnet 4.6 now reaches Opus-level performance on many office tasks.
Mermaid timeline charts Claude’s evolution:
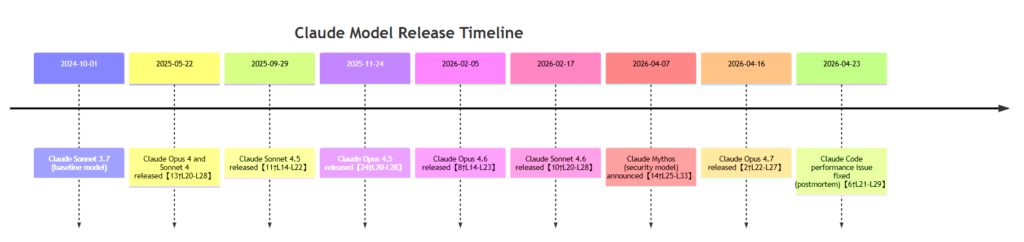
(This timeline highlights major Claude releases and relevant events. For example, Claude 4 (Opus/Sonnet 4) debuted May 2025, followed by Opus 4.5 in Nov 2025. The newest Opus 4.7 came in Apr 2026.)
Use Cases and Real-World Applications
Claude’s capabilities translate into many practical use cases across industries. Key scenarios include:
- Software Development & Automation: Claude’s strongest domain is coding. Teams use it to auto-generate code, refactor legacy systems, and act as a pair-programming partner. In fact, companies report Opus 4.x can run complex refactoring tasks (spanning multiple repos and files) to completion, catching bugs and writing tests along the way. GitHub itself notes Claude significantly boosts code comprehension and multi-step reasoning, helping Copilot handle complex codebase tasks. Organizations use Claude Code (with its IDE integrations and background agents) to automate developer workflows, code reviews, and even manage entire build pipelines.
- Knowledge Work & Business Tasks: Claude excels at research, summarization, and business analysis. It can draft reports, generate slide decks or spreadsheets, and answer domain questions. For example, Sonnet 4.6 users reported high-quality outputs in frontend development and financial data analysis. Claude can autonomously navigate spreadsheets, fill out forms, and gather web data to produce data-driven insights. In corporate settings, Claude is used for legal drafting, contract analysis, and even complex simulations (like financial modeling) because of its improved reasoning and memory.
- Creative & Design Tasks: Thanks to better vision and context understanding, Claude 4.7 helps with creative tasks. It can generate polished marketing copy, design mockups, and analyze images. Its higher-resolution image understanding makes it useful for patent analysis (identifying details in diagrams) and design prototyping (improving layouts or UX flows). Anthropic highlights life-science patent workflows where Claude reads diagrams and assists patent writing. Its improved aesthetic sense also means visual outputs (slides, GUIs) look more professional.
- AI Agents & Autonomous Assistants: A notable use is in building AI agents that perform tasks end-to-end. Claude can invoke external tools (web search, APIs, terminal) to complete tasks. In beta, Anthropic’s Managed Agents allow developers to set up multi-agent chains. For instance, you can create an automated data pipeline: Claude fetches data from cloud storage, processes it, and visualizes results. Managed Agents and the Claude Agent SDK empower advanced applications like conversational customer support bots or interactive teaching assistants.
- Cybersecurity (Defensive): While Opus 4.7 has safeguards against offensive hacking queries, its research-tier model (Mythos Preview) demonstrates Claude’s power in security analysis. In the Project Glasswing initiative, Claude Mythos found thousands of critical software vulnerabilities automatically. This shows Claude’s potential for security audits and system hardening (defensive use only). Anthropic is working with partners to use these tools defensively under a secure program.
In short, Claude’s improvements make it a versatile assistant: from writing and designing to code generation, business analysis, and workflow automation. Many enterprises (e.g. finance, tech companies, government labs) integrate Claude into their apps for these purposes, citing leaps in productivity and capability.
Pricing and Availability
Claude Sonnet models (4.x) are priced at $3 per 1M input tokens and $15 per 1M output tokens, the same as prior releases. Claude Opus models (4.x) are priced at $5 per 1M input and $25 per 1M output. Notably, Opus 4.5 (Nov 2025) introduced this lower $5/$25 pricing (down from $15/$75) to make top-tier performance more accessible. These prices are in line with OpenAI’s flagship models: for example, GPT-5.4 (formerly called GPT-4o) costs $2.50/$15, and Google’s Gemini Pro is about $2.00/$12. Claude’s models offer larger context windows (up to 1M tokens) at a flat rate, so while per-token pricing is higher, the total cost for long inputs may be similar.
All Claude models are offered via the Claude.ai platform, Anthropic’s API, and on major cloud services. Opus 4.7 and Sonnet 4.6 are available on Anthropic’s Enterprise/Team plans as well as on AWS Bedrock, Google Vertex AI, and Microsoft Foundry. (Anthropic also has specialized products like Claude for Azure Gov.) For developers, the model names are claude-sonnet-4-6 and claude-opus-4-7. Anthropic provides straightforward billing, and has removed extra premiums: the 1M-token context window (on 4.6/4.7) uses standard pricing with no premium surcharge.
In summary, Claude’s current pricing makes it competitive: Sonnet for routine tasks and Opus for high-end coding/research tasks. The flat pricing model favors workloads with huge context (like analyzing long documents) by eliminating tiered surcharges.
API Changes and Migration Guidance
Developers upgrading to Claude Opus 4.7 should note a few API and parameter changes. Anthropic provides a migration guide and even an automated Claude API skill (/claude-api migrate) to update your code. Key changes include:
- Model IDs: Change your model names to
claude-opus-4-7orclaude-sonnet-4-6in API calls. - Thinking/Extended Context: The old “enabled thinking” setting is replaced by adaptive thinking with the new
effortparameter. For example:yamlCopy// Old (Opus 4.6): thinking: {type: "enabled", budget_tokens: 32000} // New (Opus 4.7): thinking: {type: "adaptive"}, effort: "high" // no explicit budget needed(Opus 4.7 runs without thinking by default unless you set it toadaptive. Use highereffortlevels likexhighormaxfor deep reasoning.) - Sampling Parameters Removed: Parameters like
temperature,top_p,top_kare no longer used in Claude 4.7. Any non-default value will now cause an error. The model is deterministic by default; to adjust style or randomness, use prompt instructions instead. - Assistant Message Prefill: Embedding assistant instructions in the messages (
prefill) has been removed. Attempting to use prefilled messages will return an error. Instead, use system prompts or the new structured output formatting (output_config.format) to control response structure. - Output Length and Tokenization: Claude 4.7 may use up to ~35% more tokens for the same text (new tokenizer). It’s wise to increase your
max_tokensbudget (for example to 64K) when using high effort levels to allow full responses. - Default Response Style: 4.7 is more concise on simple queries and more verbose on complex ones. You may need to tweak your prompts if you expect a certain style (e.g. add “be concise” or examples). Also, it follows instructions more literally; if you relied on implicit context, you may want to make your prompts more explicit.
In practice, migrating is straightforward. Use Anthropic’s migration tool to automate the changes. If doing manually, update model IDs, remove deprecated fields, and adjust your usage of thinking and effort. Anthropic’s API reference and changelog detail all changes. Managed Agents or Cowork users simply switch the model name in their configs.
Developer Tips and Best Practices
- Use the
effortParameter: Claude 4.7 introduced fine-grained effort levels (low,medium,high,xhigh,max) to balance speed vs. intelligence. For most coding and multi-step tasks, start withxhigheffort. High or xhigh yields the best results for complex jobs, whilelowcan save tokens on simple queries. Experiment to find the sweet spot. - Allocate Sufficient Tokens: Especially with high effort, give the model plenty of output budget. Anthropic recommends starting around 64K max tokens for long-horizon tasks. Also make use of compaction to summarize context automatically and fit within limits.
- Leverage New Tools: Enable features like the Files API, Web Browser, Code Execution, and Memory in your conversation to extend Claude’s capabilities. For example, you can upload data or a PDF into Claude’s memory to maintain state across a session. Use the
output_configto get structured data back (JSON, table). - Prompt Engineering: Because 4.7 can be more literal and concise, use clear instructions and examples. Explicitly specify formats, roles, or styles as needed. If you need verbose reasoning or intermediate steps, set
thinking.display = "summarized"so you get visible progress updates. - Feedback and Testing: Take advantage of Claude’s
/feedback(thumbs up/down) to improve future outputs (opt-in for training on API). Use Anthropic’s dev playground (claude.ai) to iteratively test prompts. The new advisory tool (Expert Advisor) (in beta) can even suggest prompt improvements for you. - Monitor Usage: Keep an eye on token consumption. Use the
count_tokensendpoint to estimate costs. For very large jobs, use Batch API mode (asynchronous) to save 50% on tokens. - Stay Informed: Follow Anthropic’s release notes and system cards for detailed docs. Official resources include the Claude API docs, system card PDFs, and Anthropic’s engineering blog.
Safety, Privacy, and Limitations
Anthropic emphasizes safety and privacy. Safety: Claude 4.x models undergo rigorous alignment training. Anthropic reports that Claude Sonnet 4.6 is as safe or safer than previous models, with a “warm, honest, prosocial” character. Opus 4.6 likewise showed low rates of disallowed outputs on evaluation. In use, Claude has built-in content filters and won’t engage with prohibited queries (hate, violence, illegal advice) by design. As one example, highly sensitive cybersecurity queries are automatically blocked in Opus 4.7 to prevent misuse. Anthropic also offers Claude Gov (for U.S. government compliance) on Azure.
Privacy: For the Anthropic API (Claude for Work), inputs and outputs are not used to train models by default. Customers’ data stays private unless they opt in. Anthropic only collects data for safety review or if explicitly enabled. (Free/Pro consumer plans may opt to allow training, but enterprise API usage is protected.) Claude does not train on your documents or code without permission.
Limitations: No AI model is perfect. Claude can still hallucinate or make factual errors, especially on obscure topics. It may occasionally struggle with highly creative tasks or very ambiguous prompts. It is also “less broadly capable than Mythos Preview” for specialized tasks (e.g. cutting-edge cybersecurity). While vision has improved, it may still misinterpret very complex images. Performance can vary by prompt; achieving the best results often requires prompt tuning and proper use of new parameters.
On performance, keep in mind that Claude 4.7’s new tokenizer may consume more tokens, so long prompts cost more than before. High-effort modes, while smarter, can also cost more tokens and latency. And although Claude now handles millions of tokens, extremely long-run conversations should be designed carefully (use memories or external databases to manage state over days).
Overall, Claude Opus 4.7 is a powerful upgrade but requires developers to adapt slightly (new parameters, prompt style). The official documentation and support channels (including Discord and StackOverflow) can help with any issues.
FAQ
1. What is the latest Claude model and its release?
The newest Anthropic model is Claude Opus 4.7, released in April 2026. It’s a major upgrade for the Opus series. (Parallelly, Claude Sonnet 4.6 was released in Feb 2026.) Anthropic also previewed a research model called “Claude Mythos” for cybersecurity, but Mythos is not publicly available.
2. What are the main improvements in Claude Opus 4.7?
Opus 4.7 brings big gains in coding and reasoning. It self-plans complex coding tasks, catches its own bugs, and is more accurate on long multi-step problems. Its image understanding is much better, handling higher-res images and creating nicer visual outputs. It also supports up to 1M-token context and 128K output tokens, so it can process very long documents in one go. New controls like the effort parameter let you dial up or down its depth of reasoning, and many new tools (PDF support, browsing, code execution, etc.) are available via the API.
3. How does Claude 4.7 compare to GPT-4/GPT-4o or other models?
Claude Opus 4.7 is on par with the top LLMs for advanced tasks. Anthropic’s benchmarks show Opus 4.7 beating its predecessor and doing roughly as well as Google’s Gemini Pro or OpenAI’s latest GPT in coding and search. For example, Opus 4.6 already led on agentic coding benchmarks and web search tasks. In terms of pricing, GPT’s new model (GPT-5.4/GPT-4o) costs about $2.50/$15 per million tokens, and Gemini Pro about $2/$12. Claude’s models cost more per token ($5/$25 for Opus), but they allow up to 1M-token inputs at no extra charge. Many users find Claude better on complex, multi-step tasks like code automation, while GPT and Gemini excel in broad general knowledge. Your choice may depend on whether you need Claude’s coding strengths and large context or a cheaper model with slightly less context.
4. What are common use cases for Claude?
Claude is used in software development (auto-coding, code reviews, architecture planning), data analysis (spreadsheets, reports, financial modeling), research (summaries, drafting documents), and AI agents (automated web research, bots). It also assists design work, creating slides, graphics, or UI mockups. In short, it’s good for any work that involves complex reasoning or tool use. Enterprises deploy Claude for customer support chatbots, content generation, and even security analysis (using the Mythos model internally).
5. How do I migrate from older Claude versions to Opus 4.7?
If you use the Claude API, switch your model ID to claude-opus-4-7. Remove any deprecated parameters (sampling temp/top_p, assistant-prefill). Use the new thinking: {type: "adaptive"} with an effort setting instead of the old extended thinking. Increase your max_tokens to allow for the larger output. Anthropic provides an automated migration helper (/claude-api migrate) that updates code references and parameters. For managed agents or Cowork, usually only the model name needs updating.
6. What is the token limit and pricing for Claude 4.7?
Opus 4.7 supports up to 1,000,000 input tokens per request (with standard pricing) and up to 128,000 output tokens. Pricing for Claude Opus 4.7 is $5 per 1M input tokens and $25 per 1M output tokens. Sonnet 4.6 (the smaller model) remains at $3/$15. These rates include the long-context window at no extra cost. There are no hidden fees beyond tokens. (For comparison, GPT-4o charges about $2.50/$15 and Gemini Pro about $2/$12.)
7. How is my data handled and is Claude safe?
Anthropic does not use customer inputs/outputs from the Claude API to train its models unless you explicitly allow it. Enterprise data stays private (only optional feedback or reports might be used). On safety, Anthropic’s alignment work and system cards show Claude 4.x models have very low rates of harmful content. Content filters block disallowed requests, and Claude’s style is designed to be honest and non-toxic. In practice, Claude will refuse or safely deflect dangerous or disallowed queries. (For high-risk areas like cybersecurity, Claude’s Mythos model is gated and used only for defensive tasks.)
8. What new developer tools are available?
In addition to the API, Anthropic offers the Claude Code extension for IDEs, and a command-line CLI (ant cli) to integrate Claude into workflows. The Claude Agent SDK (introduced in late 2025) lets you build custom multi-agent applications. Claude’s Dev Mode (coming soon) will reveal its full chain-of-thought if needed. There is also a new Expert Advisor feature (in beta) that can suggest prompt improvements. All these tools are documented on the Claude developer site.
9. How does Claude handle images?
Claude 4.7’s vision capability has improved. It can ingest images (JPEG, PNG, etc.) along with text. For example, it can analyze a complex chart or design diagram you upload. The maximum image resolution is higher than before, so details are captured better. You can ask Claude questions about an image (like “what errors do you see in this circuit diagram?”) and get text answers. This makes it useful for tasks like processing scanned documents or labeling images. (Keep in mind image analysis is not unlimited – very large or numerous images may still reach practical limits.)
10. Where can I find documentation and more information?
Anthropic’s official Claude Platform Docs (docs.anthropic.com) have the latest API reference and release notes. The Claude Help Center includes tutorials and FAQs on use cases. For high-level info, Anthropic’s blog and system cards provide in-depth descriptions of each model’s abilities. All key announcements (Sonnet 4.6, Opus 4.7, etc.) are on Anthropic’s News page and linked above as sources. Developer forums and Discord channels are also active with tips.
Read More Blog-AI Startup Edge








